A Makers' Guide to AI and GPT
Published on January 28, 2023 by Caer
Even though AI seems like magic, apps aren't built on magic. So what's going on with new, magical AIs like ChatGPT? Let's cast Dispel Magic, and find out.
I recently made GPTyria, which is an app that uses AI (Artificial Intelligence) to guess which culture a quote came from in the fictional world of Tyria.

If you just want to see GPTyria in action, jump to the TL;DR!
Although GPTyria might seem like a magic box that quotes go into and guesses come out of, it isn't made of magic. Instead, it's made out of:
GPT-2, which is an AI used to convert a quote (like
"I could outrun a centaur") into an Embedding, which is a list of numbers that represent the meaning of the quote.Cosine Similarity, which is a math function that tells us how similar two embeddings are by calculating the difference in their "angle" in super-high-dimenional space.
A K-Nearest Neighbors (KNN) index, which is a list of precomputed embeddings and their labels (e.g., cultures). By searching the index for the
Kmost similar embeddings ("nearest neighbors") to an input embedding, and finding the most common label among these nearest neighbors, we can guess which culture the input embedding might belong to.
In the next few sections, we'll dive into why these tools were chosen for GPTyria, and the details of how they're used.
Embedding Quotes with GPT-2
GPTyria relies on GPT-2 to generate embeddings of quotes. GPT-2 is a kind of AI called a Machine Learning Model, or ML model for short.

ML models are (to heavily summarize) piles of math functions that are trained to recognize patterns in data, and make guesses based on those patterns. Today, they are one of the most common kinds of AI used to make apps.
The GPT-series of ML models is currently best-known for powering ChatGPT—a creepily convincing AI that can write code, draft essays, and respond to questions.
Note: GPT-2 has been superceded by the GPT-3 model, and other specialty models like ChatGPT. However, GPT-2 is the newest of the open-source GPT models.
There are superior models for the sentence embedding task done by GPTyria, like Sentence BERT. However, part of the purpose of this article is to learn more more about the GPT-series of models; thus, we use GPT-2.
Neural Networks and their Hidden Layers
GPT-2 is a kind of ML model called a Neural Network. Neural networks use math functions to infer (guess) something from multi-dimensional lists of numbers called Tensors (if you're a coder, you can think of them as arrays with one or more dimensions).
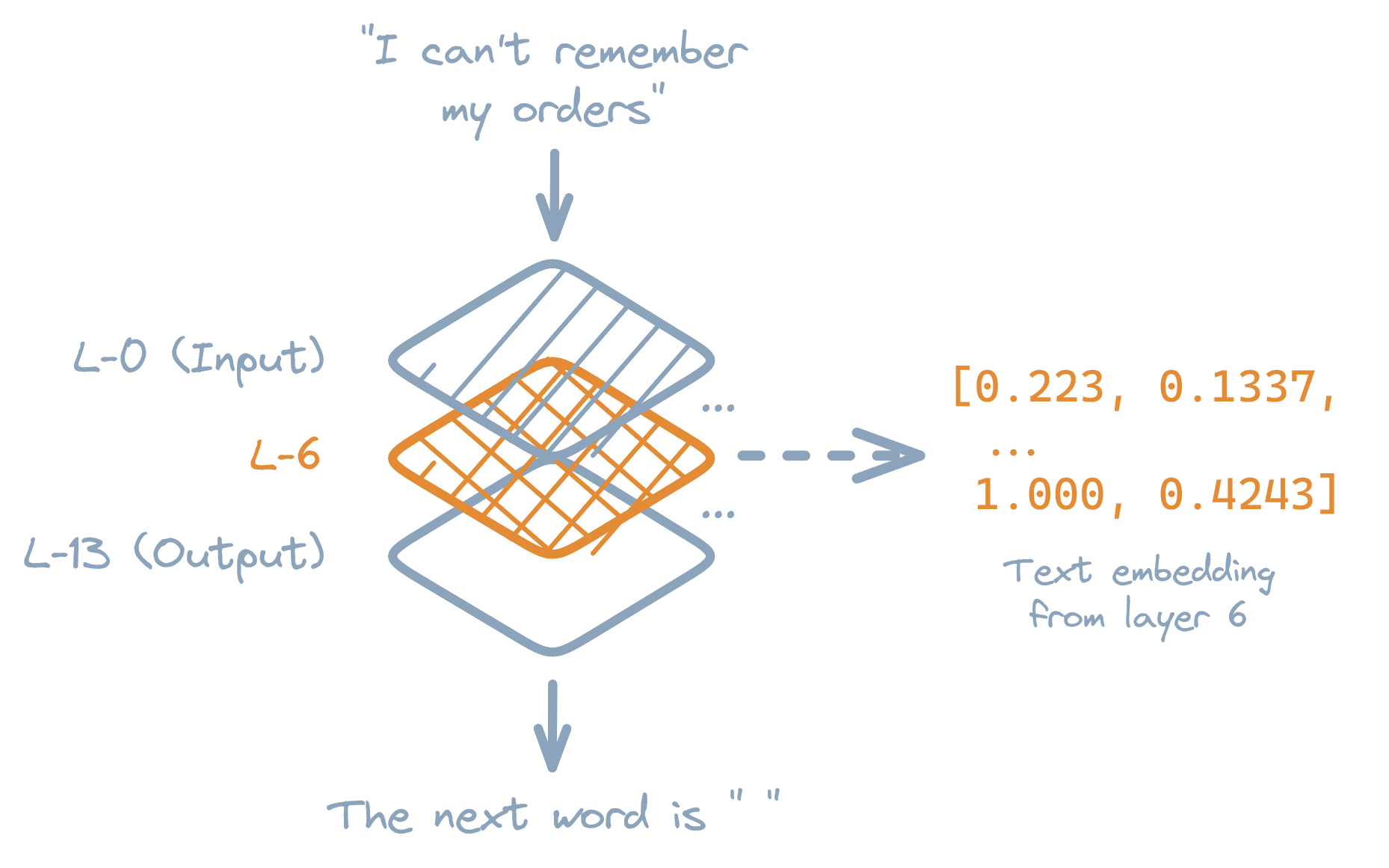
Figure: Diagram showing a subset of GPT-2's layers, and how embeddings can be extracted from the middle or "hidden" layers.
Neural networks are made from many Layers of these math functions. Like a flowchart or graph, the tensors output from one layer become the inputs of the layers after it.
Typically, the only layers a user cares about are the first and last layers: These are the layers were the models' inputs go in, and it's guesses come out. All of the layers in-between these first and last layer(s) are called Hidden Layers.
In GPTyria, we care about these hidden layers: The output tensors of each hidden layer in GPT-2 contains its inferred "meaning" of the original quote. Because tensors are lists of numbers, and GPT-2's tensors capture the meaning of text, we can use GPT-2's hidden tensors as embeddings of text.
Feature Engineering
Neural networks only accept tensors as an input, and a tensor can only contain numbers. This restriction means we need some way to turn the quotes given to GPT-2 into some initial set of numbers before we have an embedding.
To do this conversion, we need to do some Feature Engineering. Feature engineering is the process of turning Features (input data, like quotes) into tensors for an ML model to process.
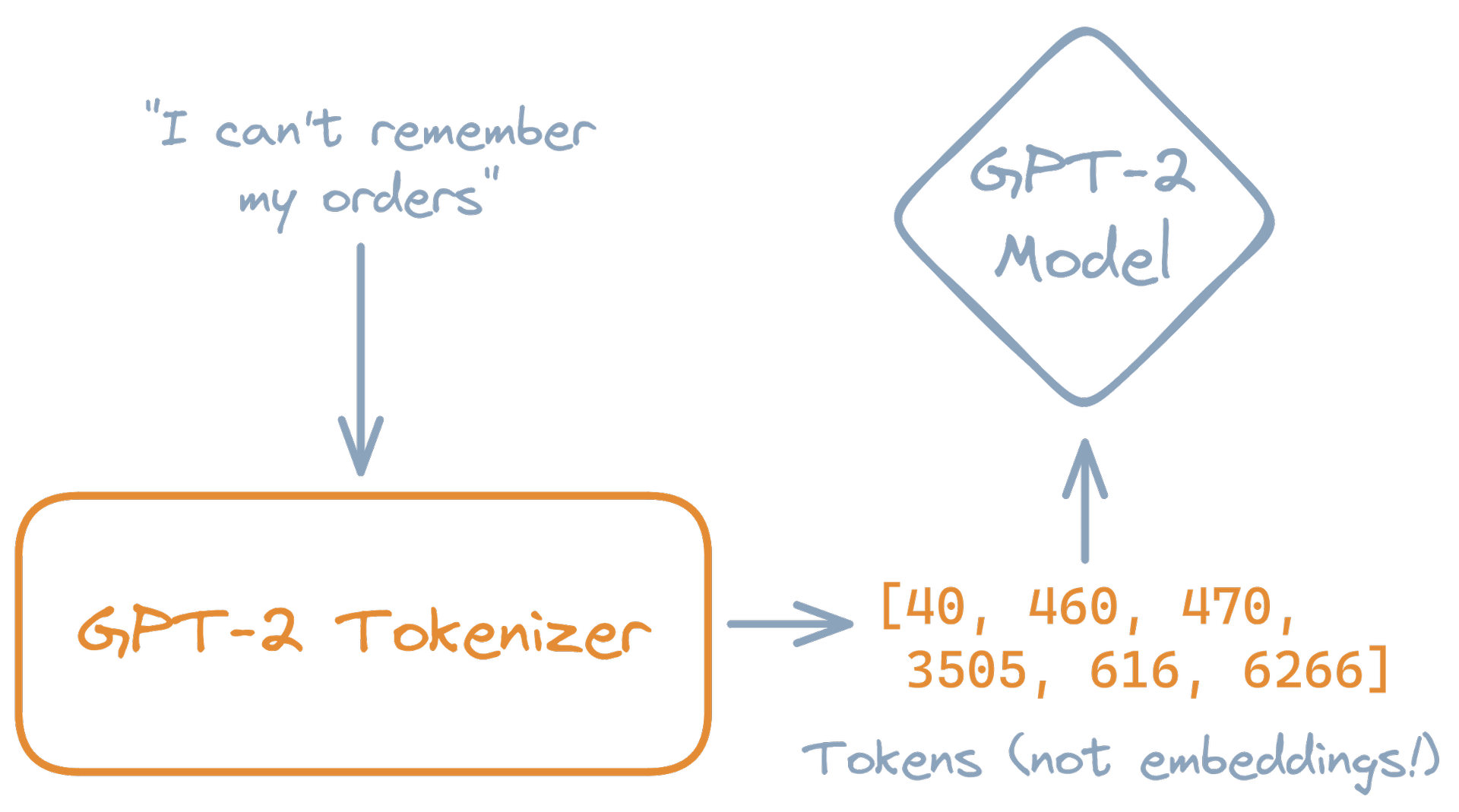
Figure: Depiction of the preprocessing step of "tokenizing" text before running the GPT-2 model.
For GPT-2, we use a feature engineering tool called a Text Tokenizer. Text tokenizers convert the characters in text into predetermined numbers or "tokens", giving us the number(s) we need to make an input tensor.
FAQ: If a tokenizer converts text to numbers, why do we need GPT-2?
By themselves, tokenizers don't capture "context" or "meaning". For example, a tokenizer will always tokenize the word "crane" as the same set of numbers.
However, the sentence "The crane flew." has wildly different meanings depending on if the crane is a bird...or construction equipment. GPT-2 is trained to understand this context, and know that the sentence probably implies the crane is a bird, and not a giant machine flying dangerously through the sky.
Using GPT-2
Using the concepts above, we can make some code that converts text into embeddings using GPT-2:
let quote = "I could outrun a centaur";
// Prepare a GPT-2 tokenizer and model.
let tokenizer = Gpt2Tokenizer::new(/* snip */);
let model = Gpt2Model::new(/* snip */);
// Tokenize the quote, truncating and/or
// padding the tokens to a length of 128.
let (tokens, padding) = tokenizer.encode_to_length(quote, 128);
// Convert the tokens into a tensor
// formatted for the model, and then
// run inference on the tokens.
let tensor = model.tensor_from_tokens(&[tokens]);
let (inference, layers) = model.infer(tensor);
// Extract the embedding from the
// hidden layers. We have to tell
// the model how much padding was
// used in the tokens, so it ignores
// any inferences that were made
// on padding data.
let embedding = model.embeddings_from_layers(layers, &[padding]);
println!("Embedding of '{}': {:?}", quote, embedding);If we run this code (which uses a Rust GPT-2 crate and Tensorflow-to-ONNX GPT-2 model I made based on OpenAI's original GPT-2 training data), we would see a message like this one:
Embedding of 'I could outrun a centaur': [[
-1.5487944, 0.25888693, 0.8932946, 0.65415406, 1.1746521,
...,
-0.32942858, 1.2995952, 1.1492503, -0.14046793, 0.8830443
]]Now that we can "embed" text, we can use these embeddings to build a mini-search engine that guesses which Tyrian culture a quote belongs to.
Labelling Embeddings with KNN
GPTyria uses a K-Nearest Neighbors (KNN) index to guess which culture an embedding belongs to. A KNN index is a collection of data entries (sometimes called Training Data), where each entry has a label associated with it.
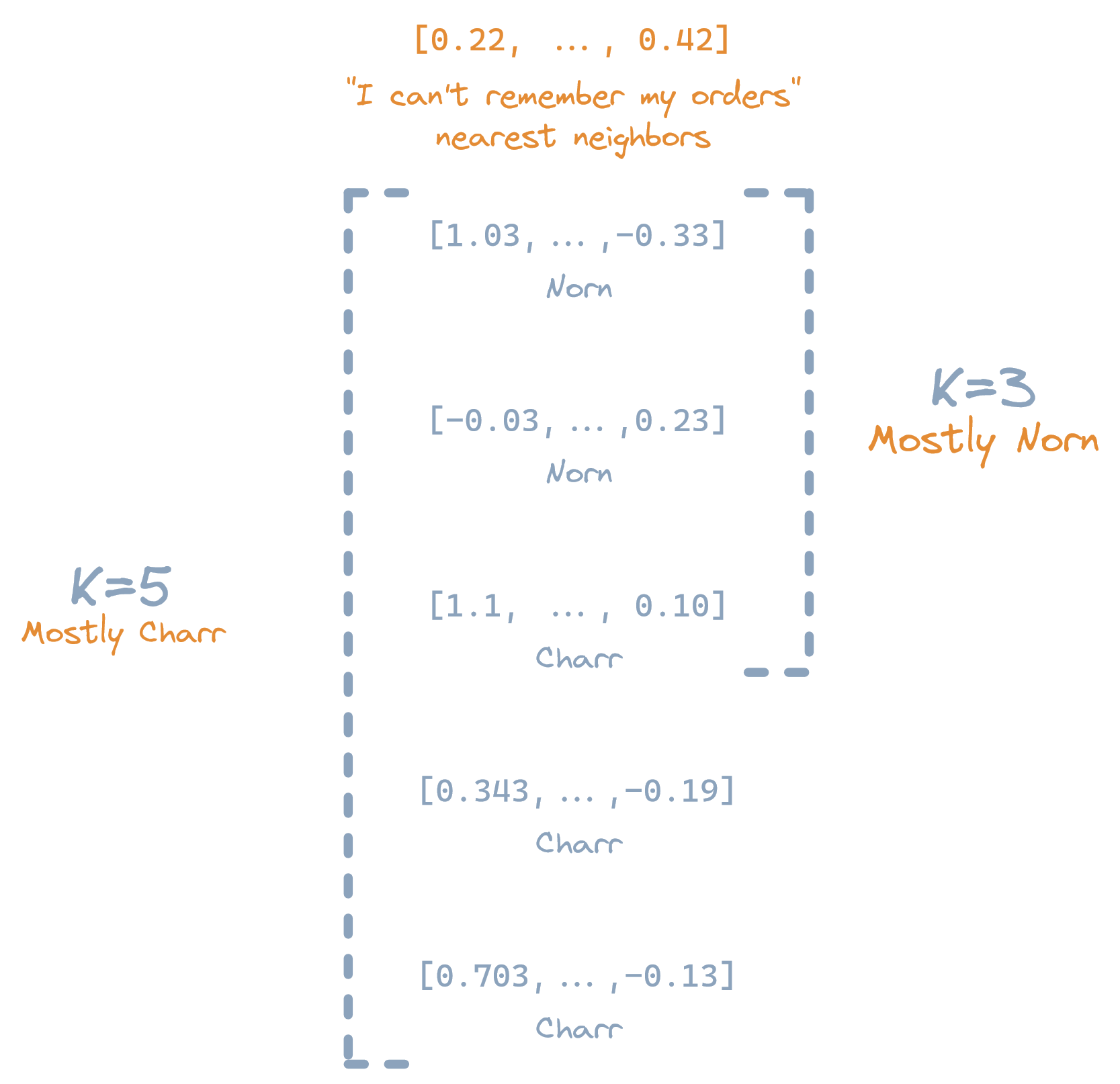
Figure: A KNN search showing how the
Kvalue can change the search result.
We can use a KNN index like a search engine by:
Scanning through the entire index, and calculating the distance between an input, and each entry in the index.
Sorting the KNN entries by their distances in ascending order.
Selecting the
Kclosest entries ("nearest neighbors") to the input.
Once this list of nearest neighbors is obtained, we can calculate the most common label among all these neighbors. This most common label is likely to be the correct label for the input.
Choosing a Distance Function
Ther are a variety of functions that can be used to measure the distance between entries in a KNN index.
Squared Euclidean distance (often referred to as L2 distance) is one of the most common and intuitive distance functions, as it simply measures the distance between two sets of points (e.g., embeddings) in space.
For GPTyria, though, we use Cosine Similarity:
fn cosine_similarity(a: &[f64], b: &[f64]) -> f64 {
let mut dot = 0f64;
let mut dot_a = 0f64;
let mut dot_b = 0f64;
// Iterate over all points `a` and `b` in
// the embeddings, creating three sums:
// - The sum of all `a * b`
// - The sum of all `a * a`
// - The sum of all `b * b`
for i in 0..a.len() {
dot += a[i] * b[i];
dot_a += a[i] * a[i];
dot_b += b[i] * b[i];
}
// Calculate the cosine similarity,
// which is the sum of all `a * b`,
// over the square root of the product
// of the sums of `a * a` and `b * b`.
dot / (dot_a * dot_b).sqrt()
}Cosine Similarity measures the difference in angle or "direction" between two sets of points. In the case of GPT-2 embeddings, it's very likely that when two embeddings have the same or similar cosines, they have similar meanings as well.
Choosing a K Value
When searching the KNN index, we need to know what value of K to use, where K is the number of nearest neighbors we want to find during the search.
The "best" K value is different for every KNN index: K values that are too small have unpredictable results (K=1 can have different results for the same input), but K values that are too large will have unchanging results (K=∞ will give the same result for any input).
In GPTyria, we select the "best" K value by:
Loading a list of quote embeddings that we know the correct cultural origin of; these are our Testing Data.
Querying the KNN index with
K=1throughK=sqrt(N)with each of the test embeddings, whereNis the total number of embeddings in the KNN index's training data.At each
Kvalue, measuring the percentage of test embeddings that were correctly labelled; this number is the Recall of the KNN index.Selecting the
Kvalue which has the highest recall.
This method of choosing K—where we compare the results of a prediction to what the actual result should have been—is sometimes called Supervised Training. The training is "supervised" because our training and testing data have been labelled ahead of time by us, and we're only asking the computer to optimize its results to match these labels.
Using a KNN Index
Although there are many libraries out there for building efficient KNN indexes, GPTyria's training data is small enough that we can implement our own KNN index rather easily:
/// Some `K` value determined ahead of time.
const K: usize = 7;
/// Build a KNN index, which is a list
/// containing pairs of `(embedding, label)`.
let knn_index = vec![/* training data */];
/// Calculate the embedding of some query quote.
let quote = "I could outrun a centaur";
let query = embed("I could outrun a centaur");
/// Search through the KNN index, calculating
/// the distance between the query and each
/// possible neighbor in the index.
let mut neighbors = vec![];
for (neighbor, label) in knn_index {
neighbors.push((query.distance_from(neighbor), label));
}
/// Sort the list of neighbors in ascending
/// order by distance, and keep only the `K`
/// nearest neighbors in the list.
neighbors.sort_by(|distance, _| distance);
neighbors.truncate(K);
/// Count up all labels among all neighbors,
/// and use the most common label as the
/// "guess" for which label the quote belongs to.
let label = most_common_label_in(neighbors);
println!("That might be a quote from a {}", quote, label);We've now covered how GPTyria converts quotes into embeddings, and uses those embeddings to guess which culture the quote belongs to. Together, these steps form the core of how GPTyria uses machine learning to guess the cultural origins of quotes.
Fun Fact: In the next section, we'll be displaying embeddings in a two-dimensional space, even though they have hundreds of dimensions.
To reduce GPT-2's 512D embeddings to a much smaller 2D, I used Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE). These are statistcial methods which convert higher-dimensional data (like embeddings) into lower-dimensional data (like 2D points). Some accuracy is lost during these conversions, but the relationship between embeddings is preserved, making PCA and t-SNE great for visualizing high-dimensional data.
TL;DR
Figure: Interactive plot of Tyrian quotes, where each quote's cultural origin has been guessed by GPTyria.
In this article, we explored how to make an app with machine learning by using:
Feature Engineering and GPT-2 to turn quotes into "embeddings" that capture the meaning of quotes as multi-dimensional arrays of numbers called tensors.
Cosine Similarity and K-Nearest Neighbors to find the
Kmost similar embeddings to a quote, and then guess the quote's culture based on the most common culture among these most similar embeddings.
Given a few example quotes, GPTyria guesses that:
"I could outrun a centaur"might be Asura (actually Krytan)"Can't remember my orders"might be Charr"I majored in pain, with a minor in suffering"might be Asura"I'll pass this along to the pale tree"might be Sylvari"Better than moot loot"might be Krytan (actually Norn)
Although these guesses aren't perfect—the iconic Krytan quote of outrunning centaurs is mis-labelled as Asuran—they're better than random guesses! If you want to try out GPTyria with your own quotes, or if you have ideas for new training data we can add to it, please check out the GPTyria code repository.
I hope that after reading this article (or at least, this tl;dr), the world of AI seems a little bit less magical, and a little bit more approachable—whether you're a maker, a gamer, or just trying to understand if ChatGPT is going to replace all of us (it probably won't...).
If you have any comments or questions about this article, you can email me at the address listed on the main page; thanks for reading!
Notice: I have no formal affiliation with OpenAI, which created the GPT-series of models, nor with Guild Wars 2, which is the video game GPTyria gets (most of) its name and training data from.
GPT-2 © OpenAI, licensed under an MIT-style license.
Guild Wars 2 Source Materials © ArenaNet LLC. All rights reserved. NCSOFT, ArenaNet, Guild Wars, Guild Wars 2: Heart of Thorns, Guild Wars 2: Path of Fire, and Guild Wars 2: End of Dragons and all associated logos, designs, and composite marks are trademarks or registered trademarks of NCSOFT Corporation.
Be the first to get my insights on tech:
Get My Newsletter
and follow me on your favorite social network
all views expressed are my own, and
don't reflect those of my clients or employers
© With Caer, LLC 2026
